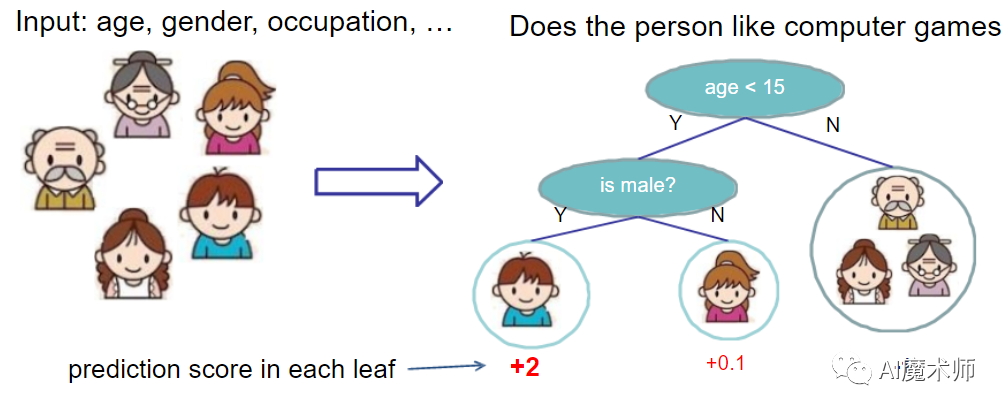
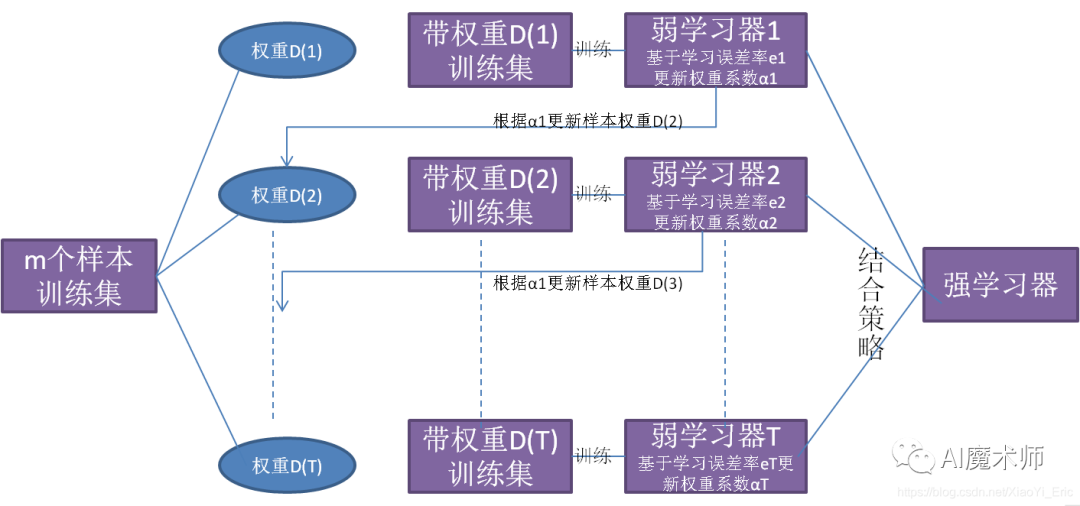
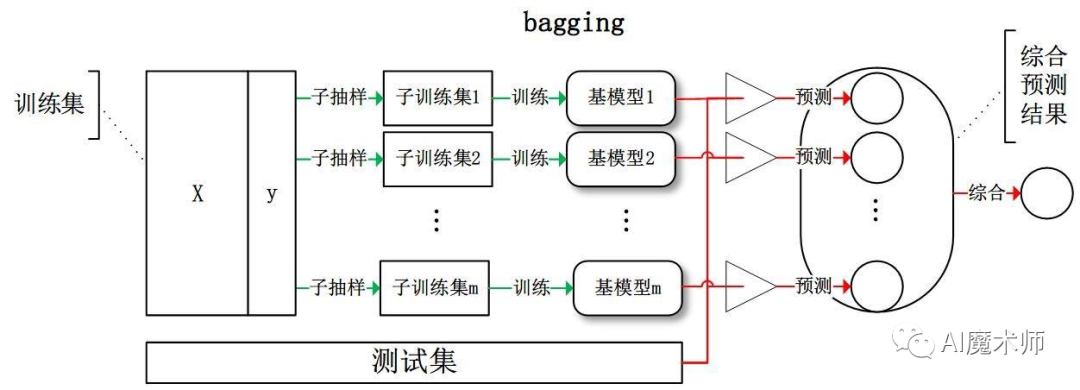
Imbalance-XgBoost和lightGBM论文导读
在学习完一系列集成学习算法之后,我们来读一读这些算法的论文吧!
leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost
研究背景
随着对booting算法的研究,XGBoost在回归和分类问题上都取得了相当大的成功,但当出现标签不平衡分类的情况时,它的性能往往变得微妙。在实践中,标签不平衡情况下的分类问题普遍存在,如果标签之间的比例出现偏差,大多数机器学习方法的性能都会下降。例如,在癌症诊断中,通常有95%的患者没有癌症,只有5%的患者患有癌症。如果模型简单地预测每个人都是“没有癌症”,那么准确率是95%,这是非常高的。然而,漏掉任何一个癌症患者都可能导致致命的后果。因此解决二元标签不平衡分类问题有着十分重要的意义。
研究内容
该论文利用Imbalance-XGBoost,将强大的XGBoost 软件与加权和焦点损失相结合,以解决二进制标签不平衡分类任务。在帕金森病数据集(最近收集的失衡数据集)进行二进制分类和UCI机器学习知识库中发表的4个基准数据集(具有失衡比例)上的二进制分类:ecoli(9:1)、心律失常(17:1)、car eval 4(26:1)和臭氧(42:1)上证明Imbalance-XGBoost的性能。
研究结果
(一)帕金森病数据集实验结果
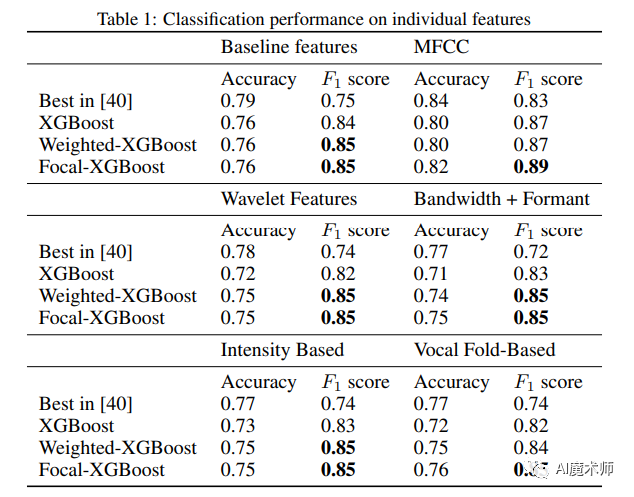
从上表可以看出Weighed-XGBoost和Focal-XGBoost的准确率略有下降,但两者都产生了显著更高的F1得分。F1的增加和准确率的下降表明,之前获得的较高的准确率是忽视少数民族阶级的结果。此外,对于几乎所有的特征组,最高的F1由Focal-XGBoost获得。这一观察结果可以从算法的角度解释,焦点损失对参数的鲁棒性更强,而加权损失容易受到次优参数的影响,即使应用参数搜索。
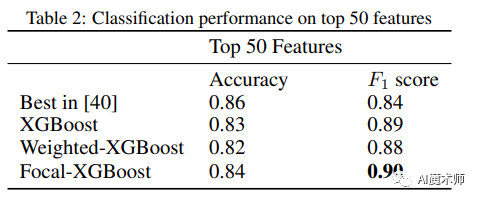
上表的实验结果与在单个特征组上的性能一致,Focal-XGBoost分类器的F1最高,略优于Weighed-XGBoost。
(二)UCI机器学习知识库中发表的4个基准数据集实验结果
从上表中可以发现,Weighed-XGBoost和Focal-XGBoost的分类精度至少与XGBoost一样具有竞争力。F1和MCC被认为是不平衡分类的最关键的指标,Weighed-XGBoost和Focal-XGBoost在所有数据集上这两个指标的表现都比普通的XGBoost好很多。此外,随着不平衡比例的上升,Weighed-XGBoost和Focal-XGBoost对F1和MCC的改善变得更加显著。
A Highly Efficient Gradient Boosting Decision Tree
研究背景
梯度提升决策树(GBDT)是一种被广泛使用的机器学习算法,因为它的效率、准确性和可解释性。GBDT在许多机器学习任务中都实现了最先进的性能,例如多类分类,点击预测,以及学习排序。近年来,随着大数据(从特征数量和实例数量两个方面)的出现,GBDT面临着新的挑战,尤其是在准确性和效率之间的权衡。传统的GBDT实现需要,对于每一个特征,扫描所有的数据实例,估计所有可能的分裂点的信息增益。因此,它们的计算复杂度将与特征的数量和实例的数量成正比。这使得这些实现在处理大数据时非常耗时。
研究内容
该论文提出了一种新的GBDT算法,名为LightGBM,它包含两种新的技术:基于梯度的单边采样和独占特征捆绑,分别处理大量数据实例和大量特征。最后在Allstate、Flight Delay、LETOR、KDD10和KKD12这5个数据集上证明了算法的性能。
数据集具体信息如下所示:
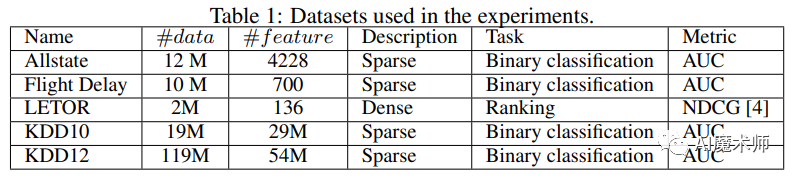
研究结果
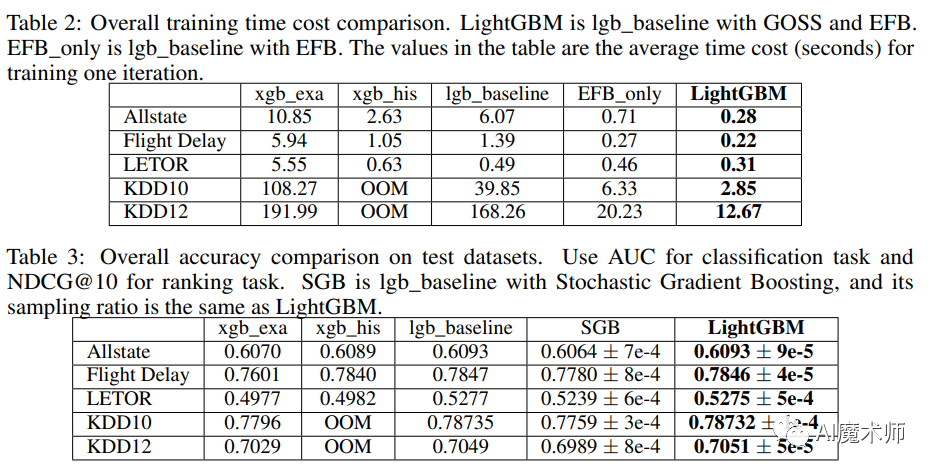
表2和表3分别为训练时间和测试精度。从这些结果中我们可以看到,LightGBM是最快的,同时保持了几乎与基线相同的精度。这表明,GOSS和EFB在带来显著加速的同时,都不会损害精度。xgbexa与xgbhis相比速度相当慢。通过与lgbbaseline比较,LightGBM在Allstate、Flight Delay、LETOR、KDD10和KDD12数据集上的速度分别提高了21x、6x、1.6x、14x和13x。由于xgbhis是相当消耗内存的,它无法在KDD10和KDD12数据集上成功运行,因为内存不足。在剩余的数据集上,LightGBM都更快,在Allstate数据集上实现了高达9倍的加速。
未来展望
在未来的工作中,可以研究基于梯度的单边采样中a和b的最优选择,并继续提高Exclusive Feature Bundling的性能,以处理大量的特征,无论它们是否稀疏。
Predicting Student Employability Through the Internship Context Using Gradient Boosting Models
研究背景
世界各地的大学都热衷于制定指导毕业生的学习计划在就业市场上取得成功。实习课程是最重要的课程之一,提供为学生提供应用知识和准备职业生涯的经验机会。然而,实习并不能保证就业能力,尤其是当一个毕业生的实习表现不令人满意,实习要求不符合。许多因素导致了这个问题如何使就业能力预测成为高等教育研究者面临的一个重要挑战。
研究内容
该论文引入一种基于上下文和使用梯度Boosting分类器的有效方法来预测学生的就业能力。学生就业能力预测依赖于识别影响毕业生就业机会的最具预测性的特征。因此,定义了两种情境模型,分别是基于学生特征的学生情境和基于实习特征的实习情境。实验使用三个梯度提升分类器进行:Extreme gradient boosting (XGBoost)、Category boosting (CatB oost)和Light gradient boosting Machine (LGBM)。得到的结果表明,与学生环境相比,在实习环境中应用LGBM分类器的效果最好。因此,本研究提供了强有力的证据,表明毕业生的就业能力在实习语境中是可预测的。
研究结果
数据集
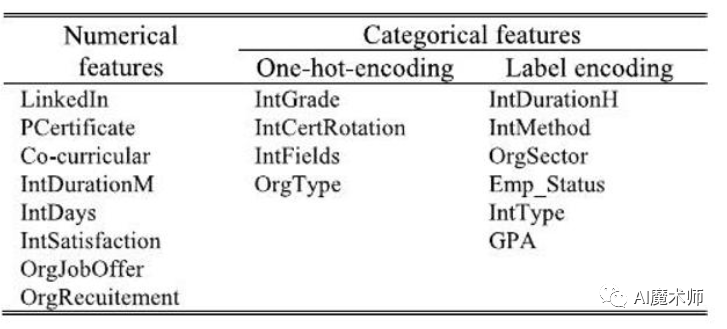
本文使用的数据基于2019年至2021年的三个学年,通过在线收集的,主要包括学生信息、实习信息以及就业信息。此外还区分了两类学习特征:学生相关特征和实习相关特征。
具体如下所示:
实验一
首先进行基础实验,实验结果如下:

从上表中可以看出CatBoost、XGBoost和LightGBM在所有选定的性能指标上都优于其他ML算法,而有序分类器如SVM、KNN和NB的得分更低。
实验二
接下来在CatBoost、XGBoost和LightGBM上进行了顶部敏感特征分析实验,确定最重要的特征,帮助改善就业状态预测任务。
实验结果下图所示:
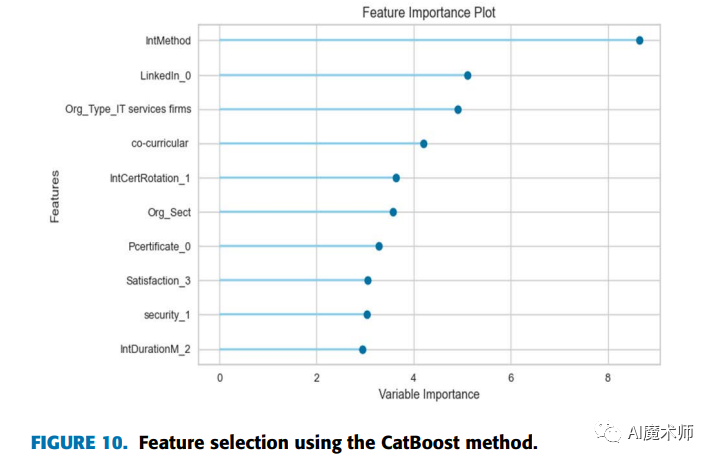
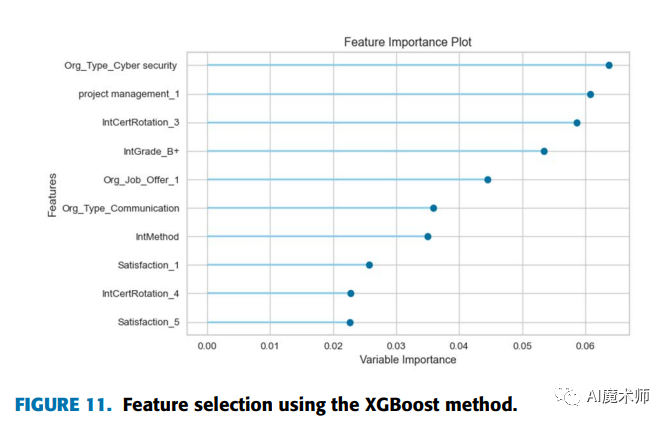
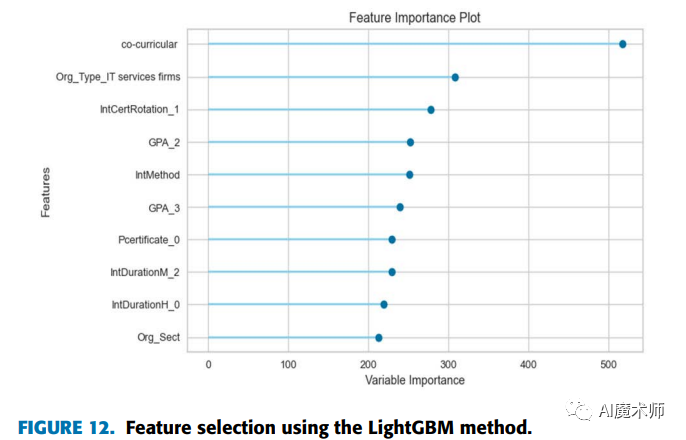
从图10中,我们注意到“intMethod”特征对使用CatBoost模型的可就业状态预测有很大的影响。在图11中,“org typeCyber security”和“project management1”特征的重要性得分最高;这意味着,在网络安全组织上进行实习会影响学生的就业能力;而且,项目管理领域的实习对学生的就业能力有着重要的影响。在图12中,协同课程特征在LightGBM模型中具有最大的重要价值。因此,学生的协同课程活动对其就业能力有很大的影响。
实验三
为了评估特征选择对预测模型性能的影响,我们比较了使用特征选择与不使用特征选择的每个模型的精度度量。
得到的结果如图13所示:
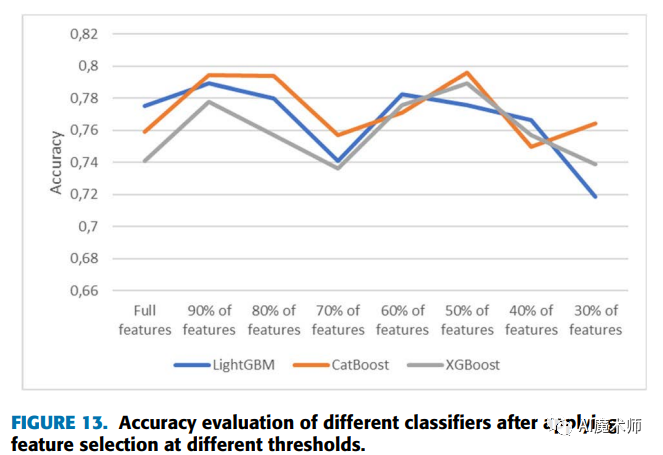
根据上图,我们观察到特征选择可以增强预测模型的准确性。与所有特征相比,在选择90%的特征时,可以看到所有模型的准确率得分的提高。此外,当选择前50%的特征时,CatBoost分类器的准确率从0.7591提高到0.7959,XGBoost分类器的准确率从0.7408提高到0.7891。而选择60%的特征时,LightGBM分类器的准确率从0.7753提高到0.7825。据此,我们可以得出结论,通过应用一种自动特征选择方法,我们可以获得更好的性能,同时通过消除无关特征来降低复杂度空间。
实验四
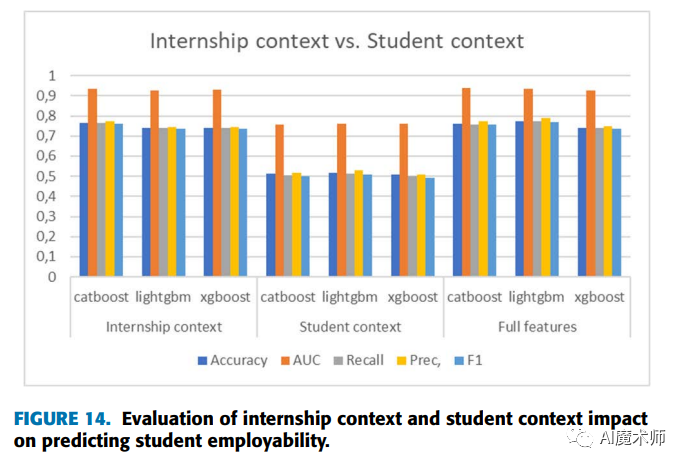
从图14可以看出,实习语境比学生语境提供了更好的结果。事实上,仅凭实习语境,我们就可以预测就业状况,准确率达76%。同时,学生情境表现最差,平均只有51%的准确率,这表明定义学生情境的特征不足以预测就业状况。因此,应该通过添加更多相关特征来进一步研究学生语境,从而帮助模型取得更好的结果。
未来展望
本研究存在两个局限性,第一个局限性为通过计算机和信息科学领域学生的实习来预测就业状况,以及对其他学科学生的其他属性的缺乏。另一个局限性是,本研究没有考虑就业率较低、有特殊需求的学生的实习背景。额外的属性会影响残疾毕业生就业状况的预测,比如语言技能和残疾类型。
未来通过实习环境来预测学生的就业能力仍然有改进的机会。学生情境可以通过附加的相关学生特征来丰富,如社会人口特征和在注册课程科目中获得的成绩,这将增加学生情境对就业能力预测的影响,甚至对实习情境的影响。来自现场实习评估的数据也很有趣,可以纳入实习背景属性,如协作、工作承诺和领导能力。除此之外,未来还可以通过实习情境预测学生的求职时长、薪资范围和就业领域。