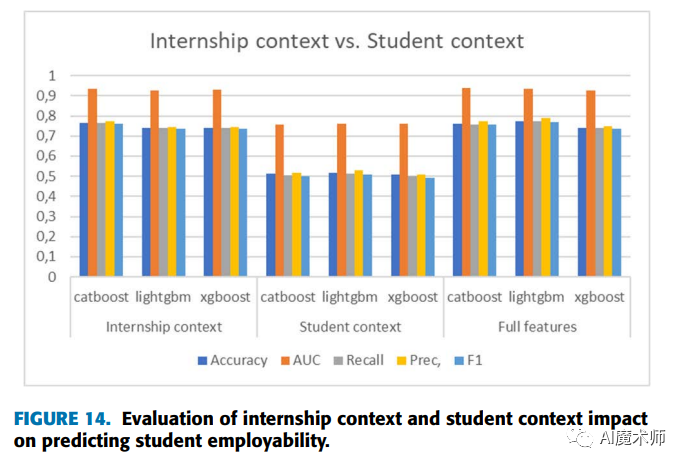
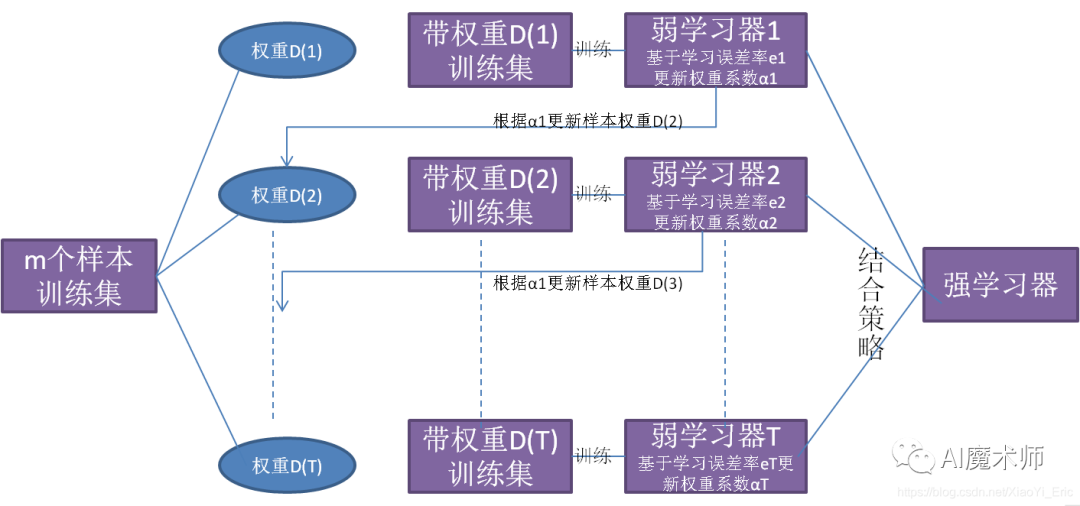
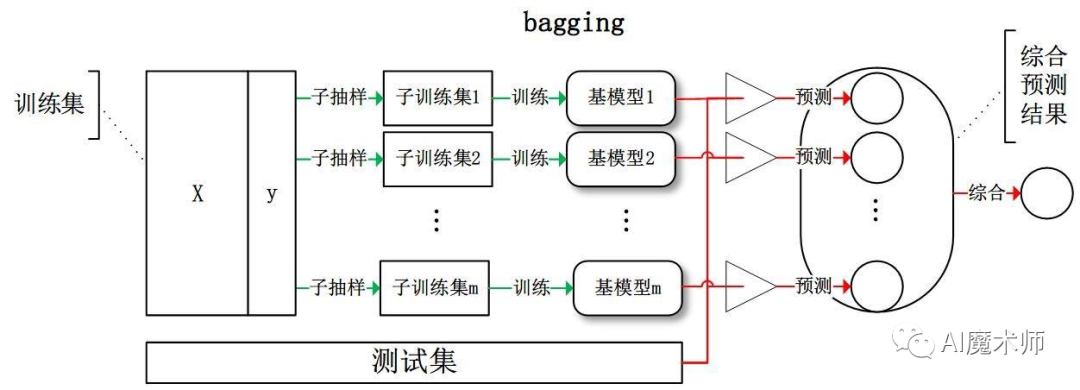
XgBoost算法
Xgboost是华盛顿大学博士陈天奇创造的一个梯度提升(Gradient Boosting)的开源框架。至今可以算是各种数据比赛中的大杀器,被大家广泛地运用。接下来就让我们一起来对Xgboost进行进一步的了解
算法介绍
Xgboost优势
由于帮助个人和团队赢得了几乎所有 Kaggle 结构化数据竞赛,XGBoost 在过去几年中获得了极大的青睐。在这些竞赛中,公司和研究人员发布数据,之后统计师和数据挖掘者竞争生成预测和描述数据的优质模型。
最初构建了 XGBoost 的 Python 和 R 的执行。由于 XGBoost 的流行,如今 XGBoost 已经实现了为 Java、Scala、Julia、Perl 和其他语言提供包。这些执行向更多的开发者开放了 XGBoost 库,并提高了它在 Kaggle 社区中的吸引力。
XGBoost 已与多种其他工具和包集成,例如适用于 Python 发烧玩家的 scikit-learn 和适用于 R 用户的 Caret。此外,XGBoost 还集成了 Apache Spark 和 Dask 等分布式处理框架。
2019 年,XGBoost 被评为 InfoWorld 令人向往的年度技术奖得主之一。
决策树
Boosting算法的思想聚焦于把许多较弱的分类器集成成为一个较强的分类器,Xgboost作为boosting算法中的其中一种,是将许多树模型集成在一起形成一个很强的分类器,因此在介绍Xgboost之前,首先需要对决策树有一个了解。
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树包括分类树和回归树,类树对离散变量做决策树,回归树对连续变量做决策树。
Xgboost算法
Xgboost算法是对梯度提升算法的改进,求解损失函数极值时使用了牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。训练时的目标函数由两部分构成,第一部分为梯度提升算法损失,第二部分为正则化项。损失函数定义为: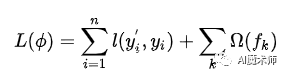
对于上式而言,y’i是整个累加模型的输出,正则化项是则表示树的复杂度的函数,值越小复杂度越低,泛化能力越强,其表达式为:
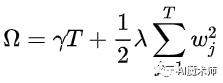
正则项是为了防止模型过拟合。于是,一般的损失函数就变成了目标函数+这样,叶子节点个数(T),节点的数值(w)。随着树的复杂度增大,对应的目标函数也就变大,这样就有效防止了过拟合。
Xgboost算法的思想是不断添加树,并不断进行特征分裂来生长树。通过学习一个新的函数,去拟合上一次预测的残差。首先我们进行训练,完成之后可以得到k棵树,我们要预测一个样本的分数就可以根据这个样本的特征,去寻找会落到每棵树中对应的一个叶子节点,所有的分数都有叶子节点与之相对应,想要得到该样本的预测值。就只需要将每棵树对应的分数加起来。
以Xgboost原作者陈天奇的讲座PPT中的例子为例,如下图所示。简单来说我们要预测一家人的身份,则可以先通过年龄是否小于15岁来区分开小孩和大人,然后再通过性别区分开是男是女。
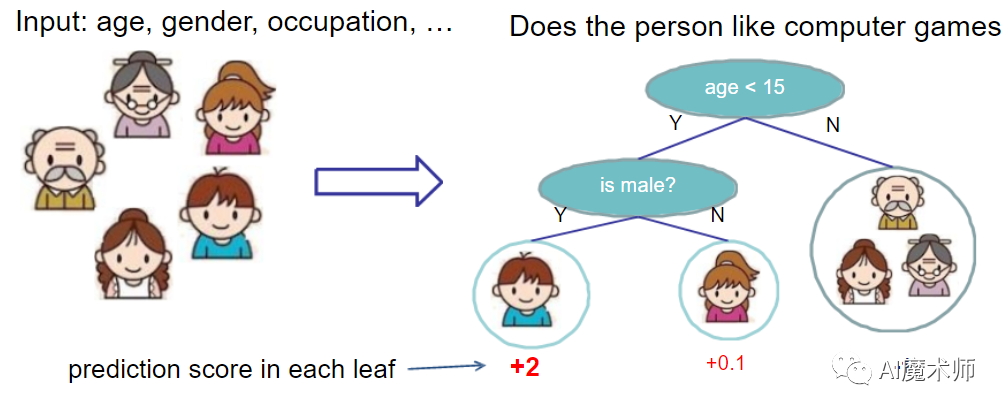
之后又通过另一个特征是否每天都使用电脑,区分不一样的样本。就这样,训练出了两棵树tree1和tree2,两棵树的结论累加起来便是最终的结论。所以两棵树中小孩所落到的结点的分数相加就是小孩的预测分数:2 + 0.9 = 2.9。同理爷爷的预测分数:-1 + (-0.9)= -1.9

Xgboost优势
① 防止过拟合
XGBoost在设计时,为了防止过拟合做了很多优化,具体如下:
1)目标函数添加正则项:叶子节点个数+叶子节点权重的L2正则化。
2)列抽样:训练的时候只用一部分特征(不考虑剩余的block块即可)。
3)子采样:每轮计算可以不使用全部样本,使算法更加保守。
4)shrinkage:可以叫学习率或步长,为了给后面的训练留出更多的学习空间。
② Xgboost不仅使用到了一阶导数,还使用二阶导数,损失更精确,还可以自定义损失。
③ XgBoost可以进行并行优化,XgBoost的并行是在特征粒度上的:
1)XGBoost的并行,并不是说每棵树可以并行训练,XGB 本质上仍然采用boosting思想,每棵树训练前需要等前面的树训练完成才能开始训练。
2)XGBoost的并行,指的是特征维度的并行:在训练之前,每个特征按特征值对样本进行预排序,并存储为Block结构,在后面查找特征分割点时可以重复使用,而且特征已经被存储为一个个block结构,那么在寻找每个特征的最佳分割点时,可以利用多线程对每个block并行计算。
④ 考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率。
对缺失值的处理方式如下:
1)在特征k上寻找最佳 split point时,不会对该列特征 missing的样本进行遍历,而只对该列特征值为non-missing 的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找split point 的时间开销。
2)在逻辑实现上,为了保证完备性,会将该特征值missing的样本分别分配到左叶子结点和右叶子结点,两种情形都计算一遍后,选择分裂后增益最大的那个方向(左分支或是右分支),作为预测时特征值缺失样本的默认分支方向。
3)如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子结点。
5.全球积极为 XGBoost 开源开发做出贡献的数据科学家数量庞大,且正在不断增长。
6.在广泛的应用中使用,包括解决回归、分类、排名和用户定义的预测挑战中的问题。
Xgboost的使用方法
sklearn库文本分类
第一步:把文本转为tfidf向量
我们可以通过用sklearn的包将文本转为tfidf向量。

x_train指的就是我们预处理的文本,用上面的代码,就可以把预处理格式的文本转为sklearn所需要的格式。然后导入sklearn里的tfidf,并将其输入到算法中。

第二步:调用sklearn的Xgboost算法

Xtrain, ytrain数据格式符合sklearn的要求即可。
Xgboost库文本分类
第一步:下载Xgboost算法包并进行导入
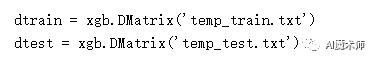
第二步:Xgboost自定义了一个数据矩阵类DMatrix,将我们的数据转为矩阵。

第三步:训练并保存模型



关于Xgboost的讲解,就是这些了,看了以上的一些内容,不知道大家对于大杀器“Xgboost”有没有进一步的了解呢?如果小编有说的不对的地方,也希望大家批评指正哦,非常感谢各位同学们看到这里,我们下期再见!
文案|肖景昌
指导老师|曹菁菁 赵强伟
排版 | 邓诗怡