导读
在前面了解了推荐算法之后,小编接下来将会介绍推荐系统架构,话不多说,咱们开始吧!
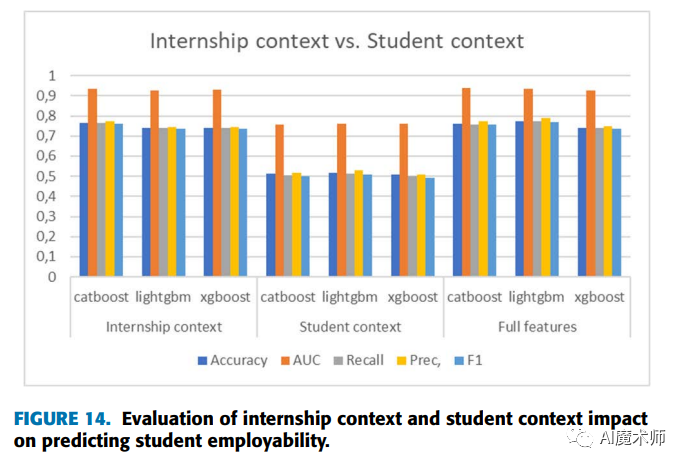
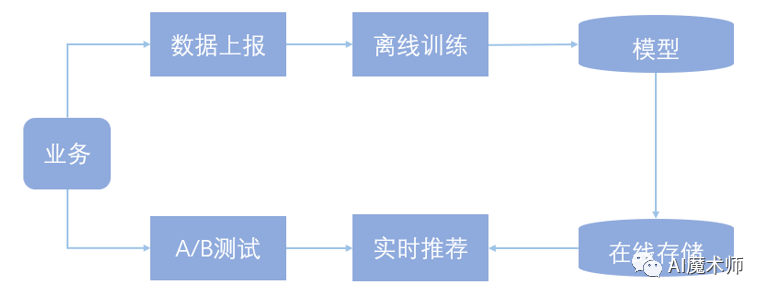
1. 基于离线训练的推荐系统架构
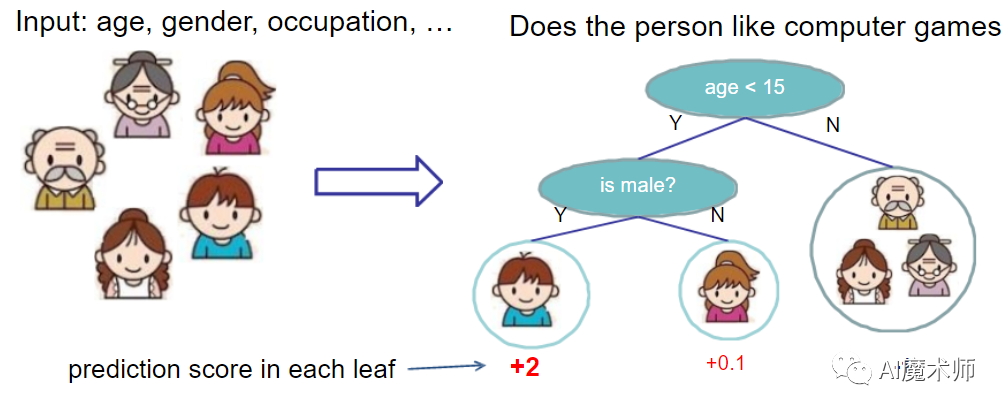
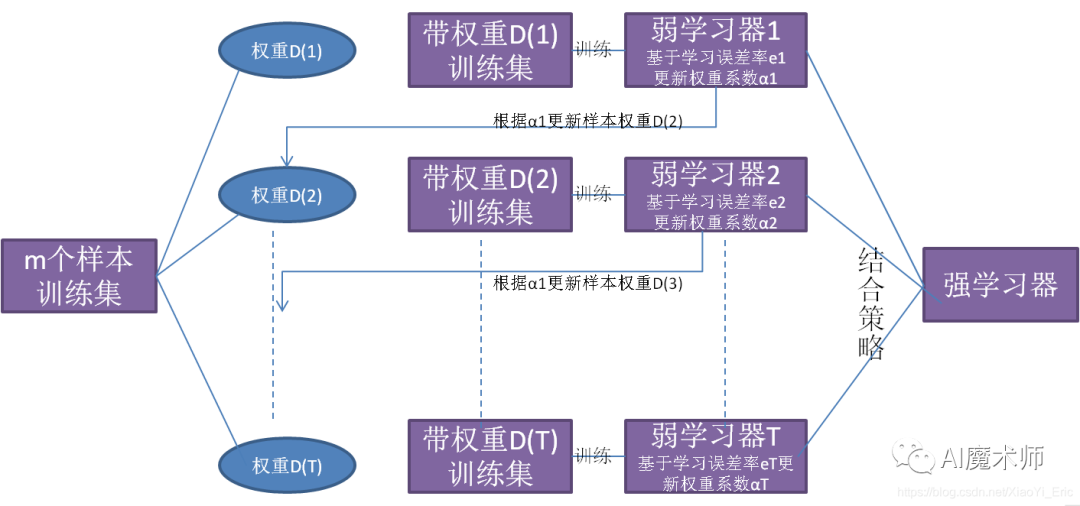
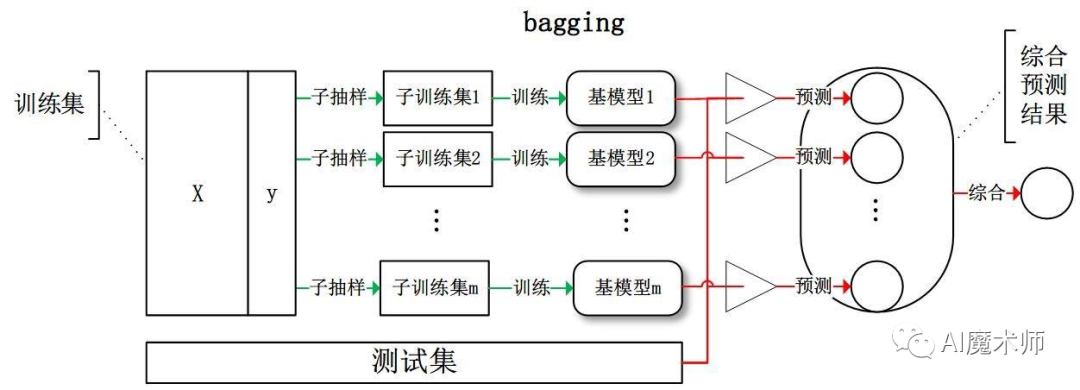
离线训练指使用历史一段时间(一周或几周)的数据进行训练,模型迭代的周期较长(一般以小时为单位),模型拟合的是用户的中长期兴趣。基于离线训练的推荐系统常用的算法有逻辑回归(Logistic Regression, RL),梯度提升决策树(Gradient Boosting Decision Tree, GBDT)和因子分解机(Factorization Machine, FM)。
如下图所示,一个典型的基于离线训练的推荐系统由数据上报、离线训练、在线存储、实时计算、AB测试几个模块组成,数据上报和离线训练组成监督学习中的学习系统,实时计算和AB测试组成预测系统,除此之外还有一个在线存储模块,用于存储模型和模型需要的特征信息实时计算模块调用。
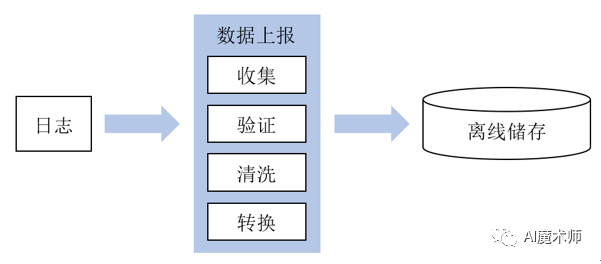
1.1 数据上报
数据上报模块主要作用为搜集业务数据组成训练样本,一般分为收集、验证、清洗和转换几个步骤。首先收集来自业务的数据。然后对上报的数据进行准确性的验证,避免上报逻辑错误、数据错位或数据缺失等问题。第三,为了保证数据的可信度,需要清理脏数据。常见的数据清理有:空值检查、数值异常、类型异常、数据去重等。最后通过数据转换,将收集的数据转换为训练所需要的样本格式,保存到离线存储模块。数据上报模块如下图所示:
1.2 离线训练
离线训练细分为离线存储和离线计算。离线存储模块通过分布式文件系统或者存储平台来存储海量用户行为数据。离线计算常见的操作有:样本抽样、特征工程、模型训练、相似度计算等,离线训练模块如下图所示:
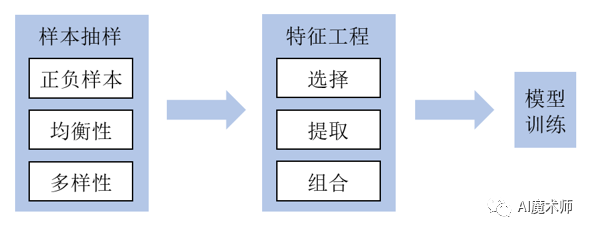
样本抽样通过合理地设计样本,为模型训练提供高质量的输入,从而训练出一个比较理想的模型。特征工程利用领域相关的知识,从原始数据中获取尽可能多的信息,组成特征用于提高模型训练效果。
1.3 在线存储
线上的服务对时延都有严格的要求,需要推荐系统在几十毫秒内处理完用户请求返回推荐结果,所以针对线上服务有一个专门的在线存储模块,负责存储用于线上的模型和特征数据。一般在线存储使用本机内存或者分布式内存。推荐系统中存储分层如下图所示: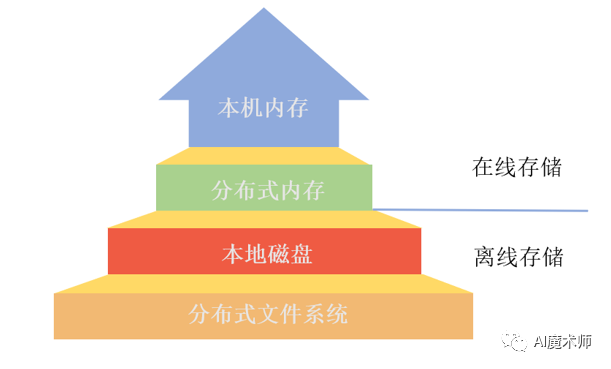
1.4 实时推荐
实时推荐模块的功能是对来自业务的新请求进行预测。一般来说该模块需要有一个分布式的计算框架来完成计算任务。常见的做法是将推荐列表生成分为召回和排序两步。更进一步,在排序得到推荐列表后,为了多样性和运营的一些考虑,还会加上第三步——重排过滤,对精排后的推荐列表进行处理。重排过滤会给用户提供一些探索性的内容,避免用户在平台上看到的内容过于同质化而失去兴趣,同时过滤掉低俗和违法的内容。常见的架构如下图所示: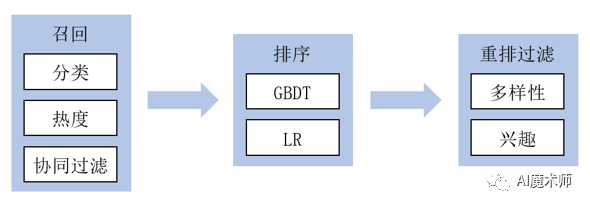
1.5 A/B测试
A/B测试基本上是一个必备模块,除了离线指标外,一个新的推荐算法上线前一般会经过A/B测试来测试新算法的有效性,另外,A/B测试模块还应包含数据可视化的功能,将统计的结果尽快地呈现给算法开发者,帮助他们快速地分析和定位问题。
2.基于在线训练的推荐系统架构设计
在线训练的推荐系统架构适合于广告和电商等高纬度大数据且对实时性要求很高的场景。基于在线训练的推荐系统不区分训练和测试阶段,每个回合都在学习,通过实时的反馈来调整策略。一方面在线训练要求其样本、特征和模型的处理都是实时的,以便推荐的内容更快地反映用户实时的喜好。另一方面在线训练并不需要将所有的训练数据都存储下来,所以不需要巨大的离线存储开销,使得系统具有很好的伸缩性,可以支持超大的数据量和模型。对于数据量很大的业务场景,基于在线训练的推荐系统提高了处理问题规模的上限,从而能够带来更多的收益。基于在线训练的推荐系统使用的常用的算法有:FTRL-Promimal、AdPredictor、Adaptive Online Learning和PBODL。基于在线训练的推荐系统架构图如下图所示: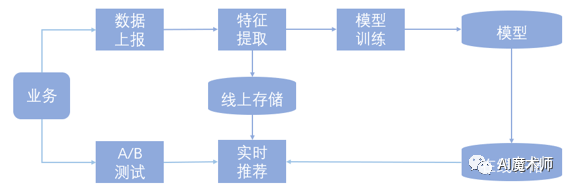
2.1 样本处理
与基于离线训练的推荐系统相比,在线训练在数据上报阶段的主要不同体现在样本处理上。对于离线训练来说,上报后的数据先是被存储到一个分布式文件系统,然后等待离线计算任务来对样本进行处理,对于在线训练来说,对样本的去重、过滤和采样等计算都需要实时进行。实时训练对于样本的正确性、采集质量和采样分布,有着更严格的要求。
2.2 实时特征
实时特征模块通过实时处理样本数据拼接训练需要的特征构造训练样本,输入流式训练模块用于更新模型。该模型的主要功能是特征拼接和特征工程。
特征拼接对特征进行读取、选择、组合等操作。首先根据算法的配置,从样本中选择需要的特征,从相应的存储接口读取该特征,将读取到的用户、物品和场景特征拼接在一起,然后根据从拼接好特征的样本中进行特征选择、特征交叉等操作,并将处理的结果写入流处理消息队列,用于输出至模型训练和模型评估模块进行流式训练。
特征工程按照特征组合规则,对特征进行内积、外积和笛卡尔积等操作,构造出新的特征,同时将新的特征和特征库写入到特征配置表中。
2.3 流式训练
流式训练模块的主要作用是使用实时训练样本来更新模型,在线训练的优势之一,是可以支持模型的稀疏存储。虽然训练使用的特征向量的维度可能是上十亿维,但是对于某一个样本实例来说可能只有几百个非零值。因此在线训练可以对大规模的数据集进行流式训练,每个训练样本只需要被处理一次。模型方面,FTRL-Proximal结合了OGD(Online Gradient Descent)和RDA(Regularized Dual Averaging)的优点,在准确度和稀疏性上比这两个模型都更优。
2.4 模型存储和加载
模型一般存储在参数服务器中,模型更新后,将模型文件推送到线上存储,并由线上服务模块动态加载。
2.5 总结
在介绍那么多之后,我们来看一下经典的架构—Netflix个性化推荐架构。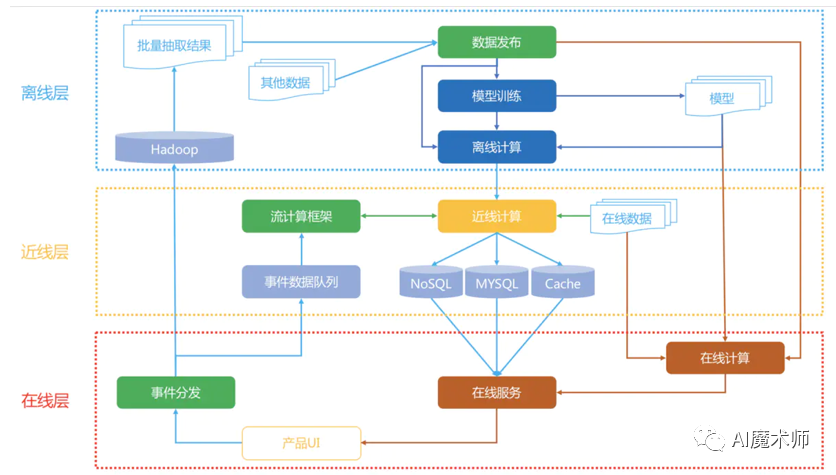 经典架构一般有三层,分别是离线,近线,在线。其对比如下表所示:
经典架构一般有三层,分别是离线,近线,在线。其对比如下表所示: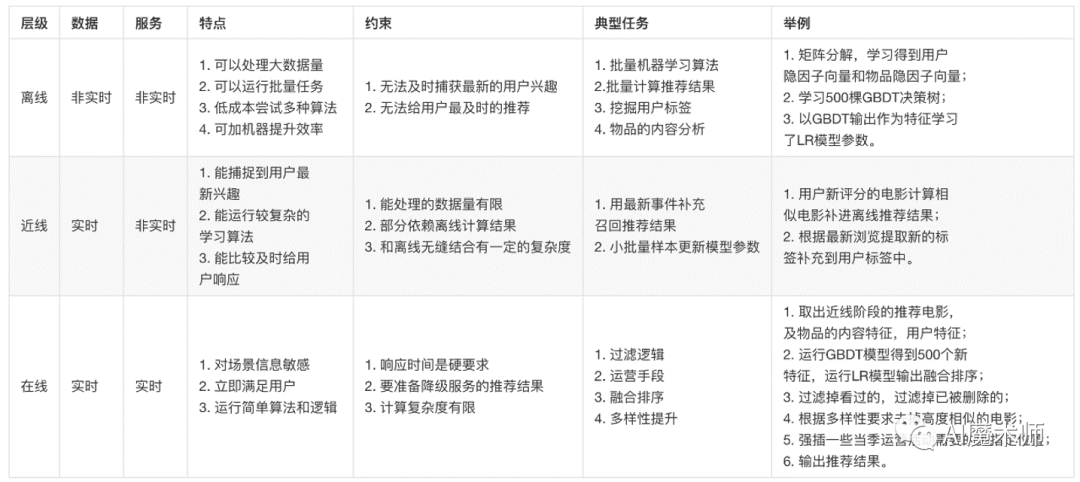 -The End-
-The End-
文案:朱琪
指导老师:曹菁菁 赵强伟
排版:余凌峰 黄雅文