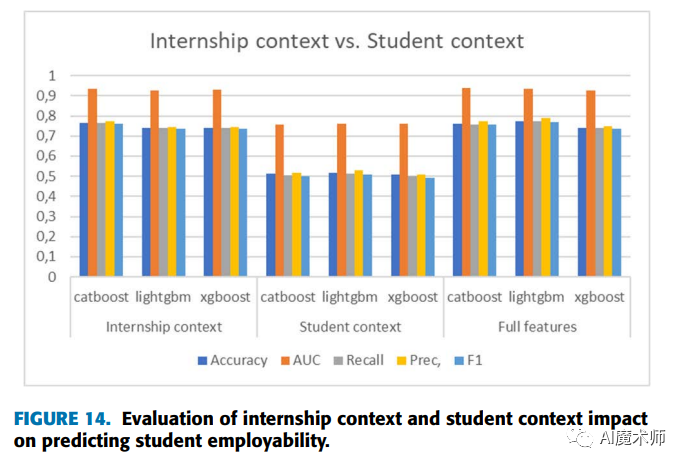
导读
最近小编接触了人体姿态估计,为了帮助大家更好的了解并学习人体姿态估计,特别推出「人体姿态估计」系列文章。作为本系列的开篇,本文详细的介绍了人体姿态估计的方法及应用,欢迎大家一起关注、阅读和讨论~
1.什么是人体姿态估计?(Human Pose Estimation)
人体姿态估计是根据图像和视频等输入数据来定位人体部位并建立人体表现形式(例如人体骨骼)。人体姿态估计可分为二维姿态估计和三维姿态估计。
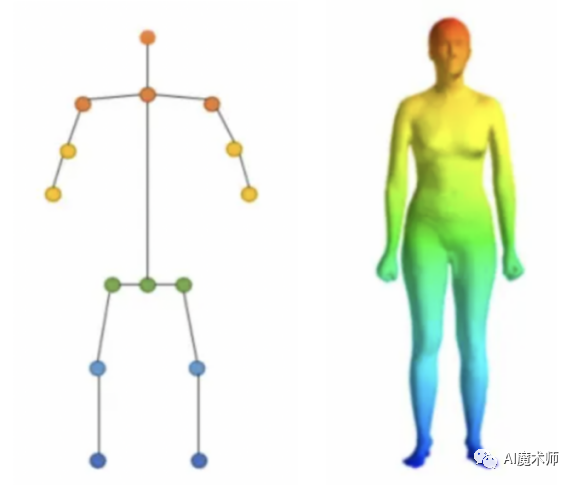
二维姿态估计指运用二维坐标(x,y)来估计RGB图像中的每个关节的二维姿态,通过像素值预测图像中的关键点。
三维姿态估计指运用三维坐标(x,y,z)来估计RGB图像中的三维姿态,通过预测关键点的三维空间排列作为其输出。

2.人体姿态估计算法(Human Pose Estimation Algorithm)
2.1 基于传统方法的人体姿态估计
传统研究的主流方式有两种:
- 第一类是直接通过一个全局特征,把人体姿态估计问题当成分类问题或回归问题直接求解。
- 第二类是基于一个图形结构模型,其思想是,将对象表示成一堆“部件”的集合,而部件的组合是可以发生形变的。一个部件表示目标对象某部分图形的模板。当部件通过像素位置和方向进行参数化后,其得到的结构可以对与姿态估计非常相关的关键点进行建模。
其缺点是什么?
- 传统方法虽然拥有较高的时间效率,但是由于其提取的特征主要是通过人工设定特征,因此无法充分利用图像信息,导致算法受制于图像中的不同外观、视角、遮挡和固有的几何模糊性。
- 同时,由于部件模型的结构单一,当人体姿态变化较大时,部件模型不能精确地刻画和表达这种形变,同一数据存在多个可行的解,即姿态估计的结果不唯一,导致传统方法适用范围受到很大限制。
2.2基于深度学习的人体姿态估计
在传统方法中,特征的提取和图结构模型在姿态估计中都扮演了非常重要的角色。随着神经网络的流行、深度学习的运用,它将特征提取、分类和空间位置建模都直接在一个“黑盒”中进行端到端的训练,这不仅方便研究人员设计与优化,而且计算处理的数据越多,检测的效果也越好。
小编根据根据现有的论文进行分类整理,为方便各位看官观看,下方贴一张目录。
目录
2.2.1 单人人体姿态估计
- 基于回归的方法
- 基于热图的方法
2.2.2 多人人体姿态估计
- 基于Bottom-up的方法(从关键点到人)
- DeepCut
- DeeperCut
- OpenPose
- Associative Embedding
- MultiPoseNet
- PersonLab
- PifPaf
- 基于Top-down的方法(从人到关键点)
- G-RMI
- Alphapose
- CPN
- HRNet
- Simple Baseline
2.2.1单人人体姿态估计
基于深度学习的单人姿态估计方法的目标是定位人体部分的关键点。
典型的单人姿态估计模型方法分为2种:一是直接从特征中回归关键点,称之为基于直接回归的方法;二是预测身体部位的大概位置或关节,通常由热图(每个图都通过以关节位置为中心的2D高斯分布来指示一个关节位置)进行监督,称之为基于热图的方法。
01 基于回归的方法
DeepPose首先尝试以非常简单的方式从完整图像中学习关节坐标,而无需使用任何人体模型或部位检测器。
它把姿态估计设计成一个关键点回归问题,并用神经网络来实现。首先输入图像,用一个7层的卷积神经网络和使用L2损失对模型进行回归训练。它克服了之前只使用局部特征的缺陷,并使用了全局的特征网络,如图下图所示。

02 基于热图的方法
基于热图的方法是从身体部位检测方法发展而来的。身体部位检测方法通常对复杂的背景和身体遮挡敏感。因此,仅具有局部外观的独立图像块可能无法很好的区分人体部位。
为了提供比关节坐标更多的监督信息并促进CNN的训练,最近的工作采用热图来指示关节的真实值。Chen等人通过采用条件生成对抗网络( GANs)的训练策略来整合人体的先验知识等等。基于热图的实例如下图所示。(a)原始图像 (b) 生成的热图 (c)检测结果。

03 两种方法优缺点
关节位置的直接回归学习是一个难题,因为它是一个高度非线性的问题,并且缺乏鲁棒性,而且不能应用于多人情况。
热映射学习则由密集的像素信息监督,具有可视化便于人类理解和对更复杂的情况进行建模,从而获得了更好的鲁棒性,然而基于热图的框架预测结果的精度依赖于热图的分辨率,这需要较高的内存消耗。
因此,对于方法选择问题 没有一个绝对的结论,每种框架都有其优点和缺点。
2.2.2多人人体姿态估计
多人人体姿态估计的主要任务是将图像中所有人体目标的关节点都检测出来,并将每个人各自的关节点划分好。多人人体姿态估计根据多人问题解决方法的不同,可以分为Bottom-up方法和Top-down方法两大类。
01 基于Bottom-up的方法(从关键点到人)
先使用一个model检测(locate)出图片中所有关键点,然后把这些关键点分组(group)到每一个人。这种方法往往速度可以实时,但是精度较差。

- DeepCut
DeepCut算法是典型的“三步走”模式:
(1)生成一个由D个关节候选项组成的候选集合。该集合代表了图像中所有人的所有关节的可能位置。在上述关节候选集中选取一个子集;
(2)为每个被选取的人体关节添加一个标签。标签是C个关节类中的一个。每个关节类代表一种关节,如“胳膊”“腿”“躯干”等;
(3)将被标记的关节划分给每个对应的人。
- DeeperCut
基于DeepCut的改进。DeeperCut主要有3个改进点:
(1)一是在关键点定位上使用了以ResNet( residual network)为基础而设计出的一种关节点检测架构;
(2)二是提出了Image-Conditioned Pairwise Terms,用以获取关键点之间关联的可能性,这一设计显著地降低了网络模型在运行时间上的消耗;
(3)三是提出了逐步优化策略来对DeepCut的整数线性规划方法进行改进。
- OpenPose
Openpose是大家最熟悉的框架,是CMU设计的世界首个基于DeepLearning的多目标姿态估计框架。
网络结构基于CPM改进,网络包含两个分支,一个分支预测heatmap,另一个分支预测paf(part affine field),paf也是这项工作的关键所在。
paf是两个关节点连接的向量场,可以把它看做肢体,以paf为基础,把group的问题转化文二分图匹配(bipartite graph)的问题,使用匈牙利算法求解。

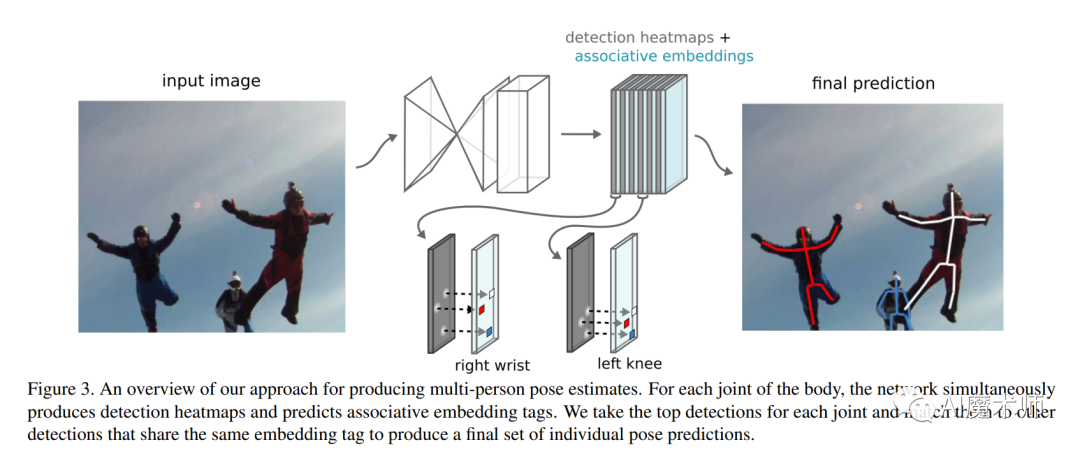
- Associative Embedding
Associative Embedding对网络模型的输出进行监督。
该方法流程先是Stacked Hourglass Architecture提取目标特征,检测多人的关键点,产生,K个channel的heatmap(其中K为关键点个数,一般为17),在产生heatmap的同时产生K个channel对应‘tag’标签,即为同一个人的关键点的tag数值都差不多,根据tag来将同一个人的关键点分到一起,这也叫为bottom-up方式,本质上为将分割级的检测通过tag变为了detection的检测。
该方法的核心思想是对Loss函数进行改进,可以更好地监督其多人网络模型的训练,同时约束模型在关节点估计和分组上的性能。
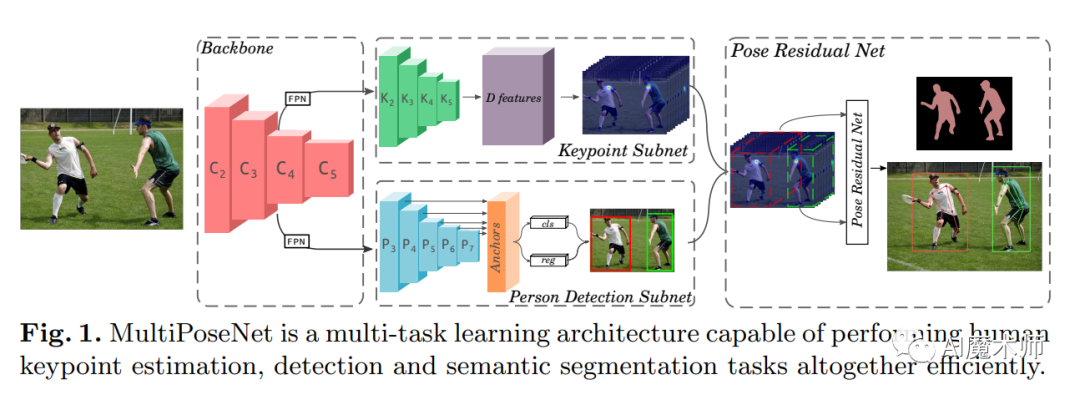
- MultiPoseNet
MultiPoseNet用于在网络中同时进行关节点定位和人体目标检测。提出了残差网络PRN(pose residual network),其目的是将人体目标检测结果用以协助关节点的分组,得到最终的人体关节点预测结果。网络架构的总体流程可分为3 部分,
第一部分是Backbone网络,用于提取图片在多尺度下的特征;
第二部分则对提取出的多尺度特征分别进行关节点定位和人体目标检测,其目标检测部分则使用了RetinaNet;
第三部分则是用PRN对定位出的关键点进行分组。这种加入了人体目标检测的方法,加强了对关节点分组的能力,提高了多人人体姿态估计的性能。
- PersonLab
G. Papandreou等提出的PersonLab架构,用于进行关节点检测和实例分割。
其网络首先对图像提取特征信息,之后分为5条并行的路线来进行关节点检测和实例分割,其中一条用于预测人体关节点heatmap,一条用于实例分割,还有3条分别获取短距、中距和远距的关节点关联关系。
其中人体姿态估计由预测人体关节点heatmap、短距和中距3条路线构成。短距信息作用于预测出的关节heatmap来提高关节点定位精度,之后使用中距信息来进行关节点的分组。在分组中提出了Fast greedy decoding来协助分组过程的进行,最终得到图像完整的关节点预测结果。

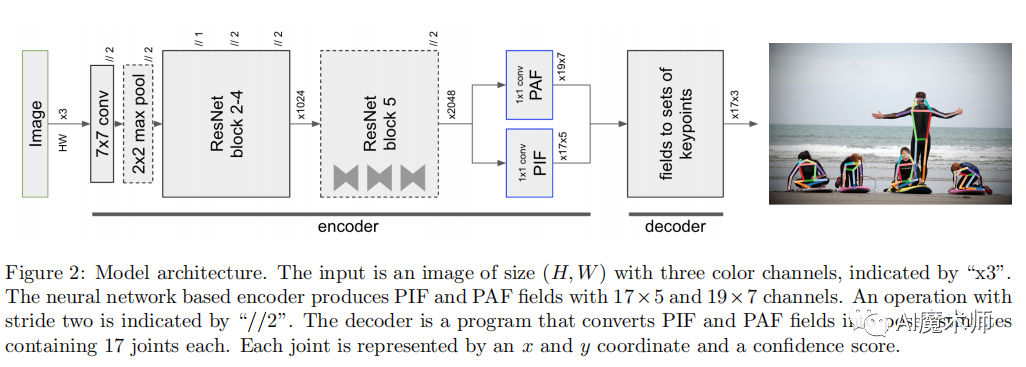
- PifPaf
该方法由Pif( part intensity field)和Paf( part association field)两部分组成,其中Pif用于定位人体关节点,而Paf则是将人体关节点各部分相互联,用于形成完整的人体姿态图。
为了将人体关节点更好地分组,设计了Greedy Decoding方法,运用Paf的结果将Pif中定位出的关节点坐标分组到同一个人。在训练时运用了Laplace loss 来进行关节点坐标的偏移量和置信度的回归,用以加强对模型的训练。
02 基于Top-down的方法(从人到关键点)
先使用detector找到图片中的所有人的bounding box,然后在对单个人进行SPPE。这个方法是Detection+SPPE,往往可以得到更好的精度,但是速度较慢。
- G-RMI
作者先由目标检测方法把人检测出来,然后再进行单人的姿态估计。具体实现过程可以分成三个阶段。
第一阶段使用faster rcnn做detection,检测出图片中的多个人,并对bounding box进行image crop;
第二阶段采用fully convolutional resnet对每一个bonding box中的人物预测dense heatmap和offset;
最后通过heatmap和offset的融合得到关键点的精确定位。
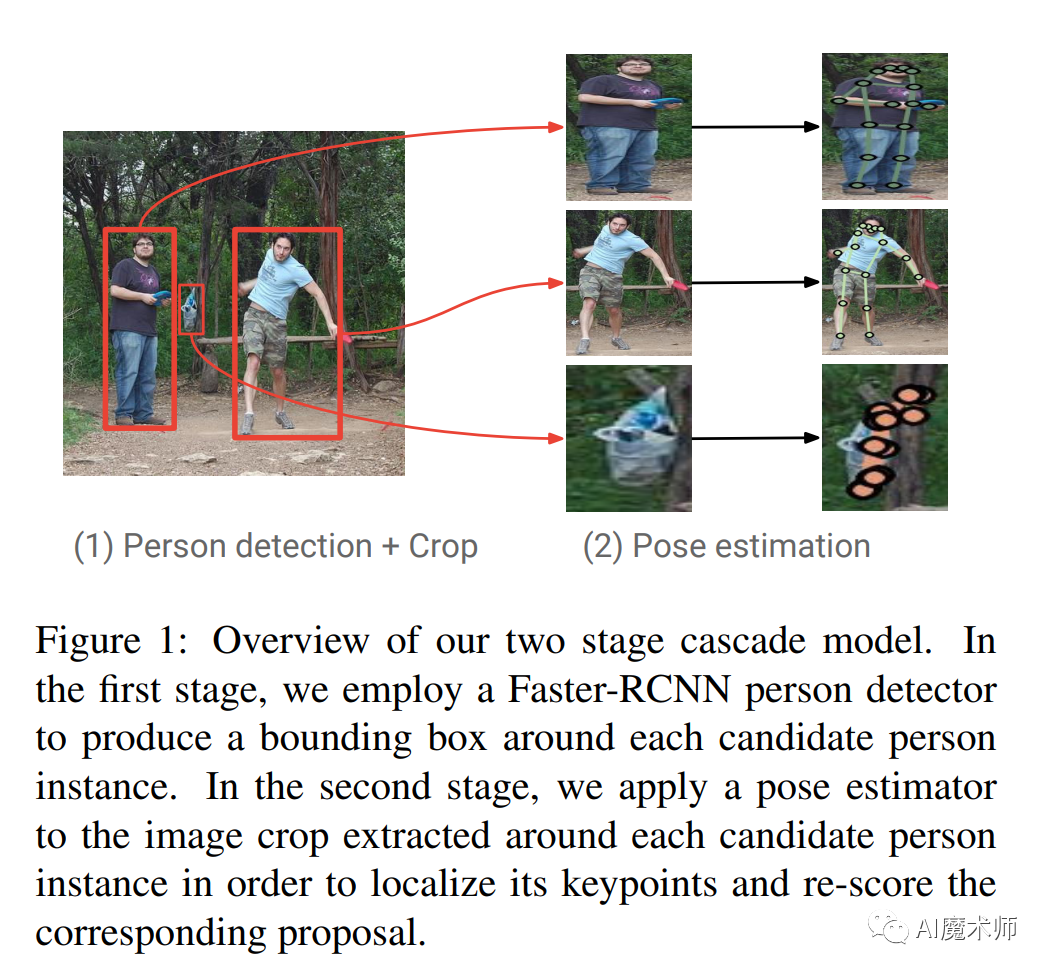
- Alphapose
H. S.Fang等认为,对人体目标进行定位和识别的时候仍然会出现一些小的误差。对此提出了RMPE框架。RPME由SSTN、Parametric Pose NMS和PGPG三部分组成,其中
SSTN(symmetric spatial transformer network) 又由提供人体目标建议的STN( spatial transformer network)和生成关节点建议的SDTN (spatial detransformer network)组成,用来解决人体目标检测结果不精确问题。
Parametric PoseNMS(parametric pose non maximum suppression) 用来解决可能出现的单目标被重复检测的问题。
PGPG( pose guided proposals generator)则是一种数据增强方法,根据人体目标的检测结果来生成更多的训练数据。RMPE的提出大大减少了人体目标检测结果不准而导致的关节点误检,同样减少了关节点分组错误的情况。
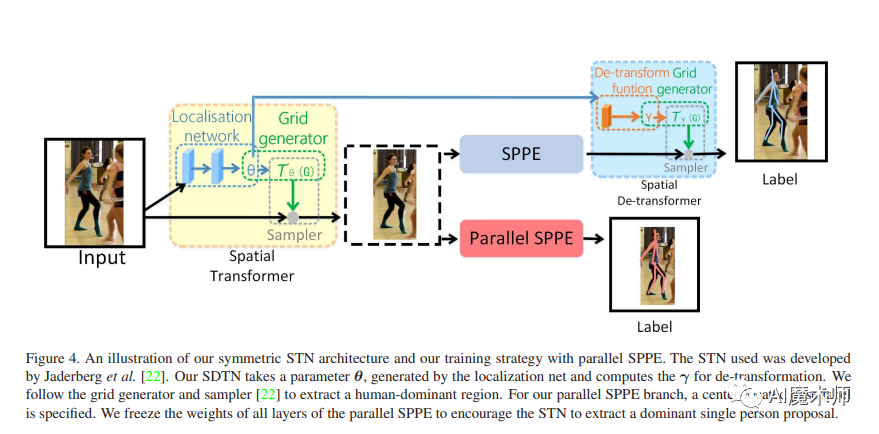
- CPN
图像中较为正面的人体关节点可以通过CNN得到很好的结果,而对遮挡较为严重的关节点进行预测比较困难,CPN结构则增强了对这些较难定位关节点的预测能力。
CPN的解决思路主要是使用更大感受野和获取更多上下文关系,即人体部位之间存在的依赖信息CPN可以分为两步:GlobalNet和RefineNet,GlobalNet 的作用是定位出易于识别的关节点,RefineNet则是对GlobalNet中提取出的不同层次特征进行融合,用以获取被遮挡点的信息,明确预测出这些较难定位关节点。
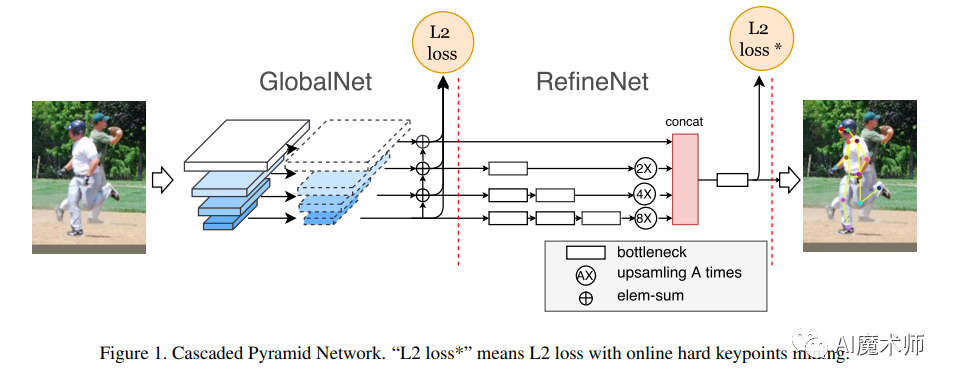
- Simple Baseline
B.Xiao等认为CPN模型都过于复杂,于是提出一个既简单又高效的Simple Baseline架构。
Simple Baseline首先检测图像中所有的人体目标,之后通过他们提出的网络架构来预测每个人体目标的关节点。其预测关节点的网络架构以ResNet为基础改变而来,将ResNet最后的全连接层换成3个反卷积层和一个1×1的卷积层。
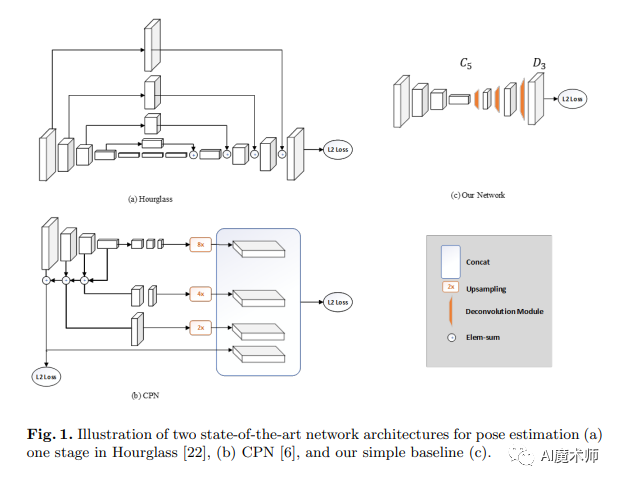
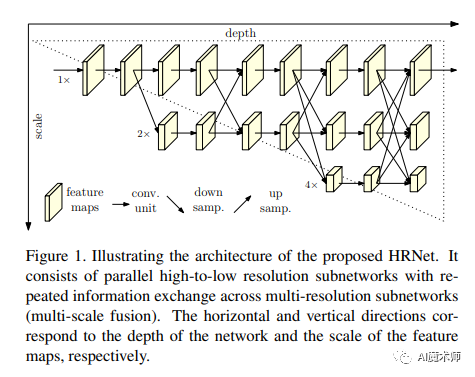
- HRNet
CPN和Simple Baseline等模型在提取特征时,均是先从高分辨率到低分辨率再从低分辨率到高分辨率的一个过程。K.Sun等认为这种做法可能会丢失高分辨率的特征图信息。针对这一问题提出了HRNet( high-resolution net)。HRNet增加了对高分辨率特征图的提取与保留,使网络进行低分辨率的特征提取时,并行地进行更高分辨率的特征提取。
3.人体姿态估计的应用(Application of human pose estimation)
3.1 运动分析
如视频所示,人体姿态估计可以检索运动员的动作,提取运动员的各项技术参数(如关节位置、角度和角速度等),通过分析这些信息,可以为运动员的训练提供指导和建议,有助于提高运动员的训练水平。
3.2 动作捕捉
人体姿态估计可以应用在电影制造技术上,检测出人体姿态之后,图形、风格、特效增强、设备和艺术造型等就可以被加载在人体上,通过追踪人体姿态的变化,渲染的图形可以在人动的时候“自然”地与人“融合”。

《刺杀小说家》中的黑甲如果不说他是郭京飞扮演,估计很多观众都看不出来,这人物正是使用了面部、动作捕捉后,后期再叠加特效人物,在电影中虽然看着不是他们的脸,但又完全是他们本人。
3.3 智能监控
智能监控与一般普通监控的区别主要在于将人体姿态识别技术嵌入视频服务器中, 运用算法, 识别、判断监控画面场景中的动态物体--行人、车辆的行为, 提取其中关键信息, 当出现异常行为时, 及时向用户发出警报。
固定场景下的人体姿态识别技术可以应用于家庭监控, 如为了预防独居老人摔倒情况的发生, 可以通过在家中安装识别摔倒姿态的智能监控设备, 对独居老年人摔倒情况的识别, 当出现紧急情况时及时做出响应。
3.4 游戏娱乐
人体姿态估计也可以应用在人机交互、游戏娱乐,比如体感游戏就是通过对人体运动姿态进行识别来实现游戏互动的,抖音、快手等视频软件上的一些动作特效也是通过人体姿态估计实现的。

4.参考文献(Reference)
[1] Toshev A , Szegedy C . DeepPose: Human Pose Estimation via Deep Neural Networks[J]. IEEE, 2013.
[2] CHEN X,YUILLE A. Articulated pose estimation by a graphical model with image dependent pairwise relations[J]. arXiv preprint arXiv: 1407.3399,2014.
[3] Pishchulin L , Insafutdinov E , Tang S , et al. DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation[J]. IEEE, 2016.
[4] Insafutdinov E , Pishchulin L , Andres B , et al. DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model[J]. arXiv e-prints, 2016.
[5] Zhe C , Simon T , Wei S E , et al. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields[J]. IEEE, 2017.
[6] Newell A , Huang Z , Deng J . Associative Embedding: End-to-End Learning for Joint Detection and Grouping[J]. 2016.
[7] Kocabas M , Karagoz S , Akbas E . MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network[J]. Springer, Cham, 2018.
[8] Papandreou G , Zhu T , Chen L C , et al. PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model[J]. Springer, Cham, 2018.
[9] Kreiss S , Bertoni L , Alahi A . PifPaf: Composite Fields for Human Pose Estimation[J]. arXiv e-prints, 2019.
[10] Papandreou G , Zhu T , Kanazawa N , et al. Towards Accurate Multi-person Pose Estimation in the Wild[J]. IEEE, 2017.
[11] Fang H S , Xie S , Tai Y W , et al. RMPE: Regional Multi-person Pose Estimation[J]. IEEE, 2017.
[12] Chen Y , Wang Z , Peng Y , et al. Cascaded Pyramid Network for Multi-Person Pose Estimation[J].
[13] Xiao B , Wu H , Wei Y . Simple Baselines for Human Pose Estimation and Tracking[J]. arXiv e-prints, 2018.
[14] Sun K , Xiao B , Liu D , et al. Deep High-Resolution Representation Learning for Human Pose Estimation[J]. arXiv e-prints, 2019.
[15] 彭帅, 黄宏博, 陈伟骏,等. 基于卷积神经网络的人体姿态估计算法综述[J]. 北京信息科技大学学报:自然科学版, 2020, 35(3):8.
[16] 张静静, 宁媛, 章成学. 深度学习的二维人体姿态估计综述[J]. 智能计算机与应用, 2021, 11(6):5.
[17] 岳程宇, 闫胜业. 2D人体姿态估计综述[J]. 现代信息科技, 2020, 4(12):3.
-The End-
文案:黄雅文 王雪
指导老师:曹菁菁 赵强伟
排版:王雪