✦ 前言 ✦
本文对语义分割(Semantic segmentation)的基础知识进行总结,主要包括图像分割类别、基本原理、常用运算及评价指标、常用数据集、经典分割网络五部分。请新手入门的朋友放心食用。
1.深度学习的图像分割分类
深度学习的图像分割按分割目的可分为语义分割、实例分割以及全景分割三类:
语义分割(Semantic Segmentation)是对图像中每个像素进行分类,从而将图像分割成几个含有不同类别信息的区域;
实例分割(Instance Segmentation)是在语义分割的基础上将同类物体中的不同个体的像素区分开;
全景分割(Panoptic Segmentation)则是语义分割和实例分割的结合。不同于实例分割只对图像中的物体进行检测和分割,全景分割是对图中的所有物体包括背景都进行检测和分割。
可见实例分割和全景分割都是在语义分割的基础上发展而来的。
三种分割的区别如下:

2.语义分割的基本原理
基于卷积神经网络的语义分割模型是语义分割的主要方法。
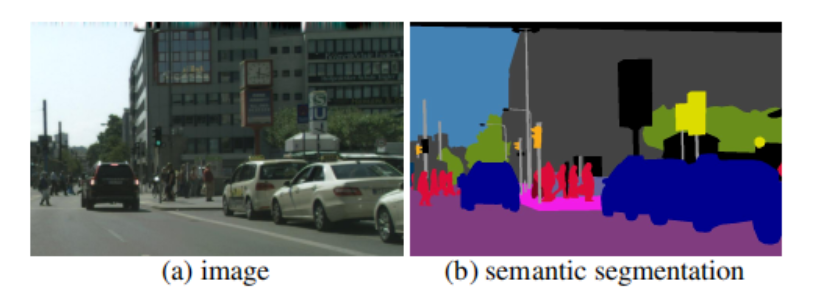
语义分割的原理可概括为:以尺寸为H×W×3的RGB图像作为语义分割模型的输入,其中H代表图像的高,W代表图像的宽,3代表RGB三个颜色通道。语义分割模型对输入交替进行卷积操作、池化操作以及上采样操作,从而得到尺寸为H×W×N的输出,其中N代表分类的类别数。在输出的空间维度H×W上的每一个元素都是含有N个数值的一维向量,若其中的第i个数值最大,则表示该元素对应的像素更可能属于第i类。通过选出每个向量中最大值对应的类别数,可将该输出转变为尺寸为H×W×1的逐像素标签。进一步对每一类像素标签用特定的颜色表示,即可得到输入图像的语义分割结果。

上图展示了语义分割模型的输入图像和输出的逐像素标签。为了清晰起见,对逐像素标签进行了简化,实际上逐像素标签与图像的像素是一一匹配的。输入图像含有人、包、植物、人行道以及建筑共5个类别。经过语义分割模型的运算以后,得到了输出的逐像素标签。在逐像素标签中,每个数值表示图像中对应位置的像素是属于该数值对应的类别。逐像素标签中1代表人,2代表包,3代表植物,4代表人行道,5代表建筑。进一步将人的像素区域表示为红色,将包的像素区域表示为紫色,将植物的像素区域表示为绿色,将人行道的像素区域表示为灰色,以及将建筑的像素区域表示为黄色,就可以得到图像的语义分割图。
3.语义分割的常用运算及评价指标
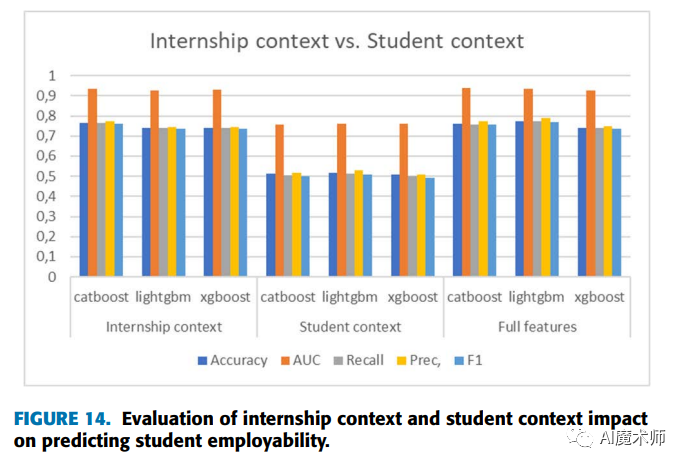
语义分割模型会对输入图像交替进行卷积运算、池化运算、以及转置卷积运算,从而将输入图像转变为逐像素标签。在模型的训练过程中,需要依据损失函数来不断更新模型参数,语义分割任务中常用的损失函数是交叉熵损失函数。语义分割任务采用mIoU(mean Intersection over Union)这一指标来衡量语义分割模型的分割性能。以下将逐一介绍语义分割的常用运算、交叉熵损失函数及评价指标。
(1)卷积运算
卷积运算(卷积层)是卷积核对图像或特征图做自左向右,自上而下的加权和运算。

如上图所示,卷积核的尺寸为H×W×C,H代表高,W代表宽,C代表厚度。卷积核中的每个小方格都代表一个参数,即卷积核的权值。卷积核的尺寸是人为给定的,卷积核中的参数是不断学习得到的。在卷积运算中,往往会使用多个卷积核。卷积核的厚度与个数的区别如下:卷积核的厚度为被卷积的图像的通道数;卷积核的个数为卷积运算后输出的通道数。

如上图所示,以尺寸为3×3×1的卷积核对尺寸为5×5×1的输入卷积为例对卷积运算进行说明。卷积核在输入的空间维度上自左向右、自上而下地滑动,每滑动到一个区域,就将卷积核中的值与当前区域中同位置的值相乘,然后将结果加和为单个输出值。卷积核重复这个过程直到遍历了整个输入,得到了尺寸为3×3×1的输出。输出特征实质上是在输入数据相同位置上的加权和。
在卷积神经网络中,卷积运算的输入往往有多个通道,且往往存在多个卷积核。每个卷积核对输入进行运算后都会得到一个通道数为1的输出,通过将所有卷积核的输出沿通道维度拼接起来就可以得到通道数为卷积核个数的卷积运算输出。
(2)池化运算
在卷积神经网络中,池化运算用于对输入下采样和提取特征。池化运算的具体做法是在输入上做划窗操作(即池化区域在输入上自左向右、自上而下地滑动),并将划窗内的所有值用一个值代替。若在池化运算时选取划窗内的最大值,则称为最大池化;若选取划窗内所有值的平均值,则称为平均池化。语义分割模型常采用最大池化。
下图展示了最大池化的运算过程。图中池化区域大小为3×3,其在尺寸为5×5×1的输入上进行最大池化运算,即取每个划窗位置内所有值的最大值并输出。在池化区域遍历完整个输入后,得到了尺寸为3×3×1的输出。池化运算往往是在多通道的输入上进行的,多通道的输入经过池化操作后空间尺寸(即宽和高)会发生变化,但通道数不变。

(3)转置卷积运算
池化运算可以对输入进行下采样,而转置卷积运算则用于对输入进行上采样。转置卷积实质上是对输入进行零填充(zero padding)操作后再进行卷积运算,从而达到增大输入空间尺寸的目的。

如上图所示,对于尺寸为2×2×1的输入,转置卷积运算首先对输入的空间维度进行两周零填充,即在输入空间维度的上下左右添加0像素。此后采用尺寸为3×3×1的卷积核对变形后的输入进行卷积运算,最后得到了尺寸为4×4×1的输出。转置卷积运算往往也作用于多通道输入,且常使用多个卷积核。
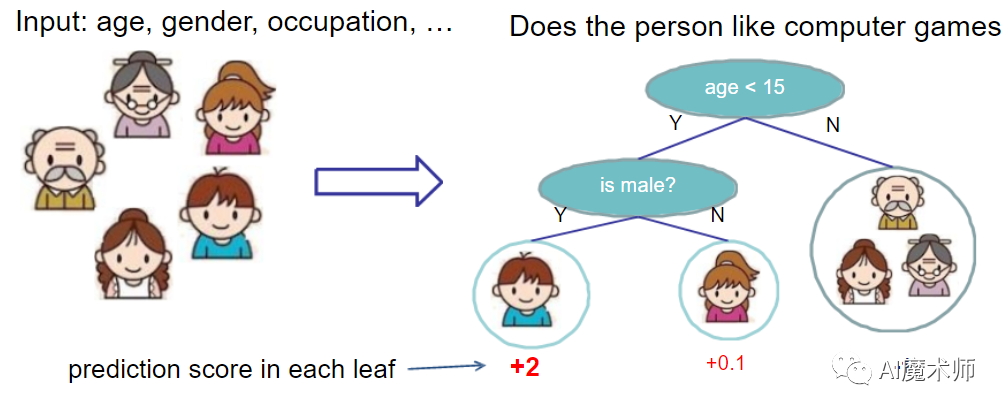
(4)交叉熵损失函数
交叉熵损失函数是语义分割任务中常用的损失函数。在语义分割网络的训练过程中,需要根据损失函数来更新网络的参数。在进行交叉熵损失函数计算之前,需要将语义分割网络的末端输出沿通道维进行softmax函数运算。末端输出的尺寸为H×W×N,N代表分类的类别数,采用softmax函数对通道维进行运算,即可得到每个像素属于每个类别的概率值。softmax函数如下:

其中x为末端输出空间维度的某一像素,是大小为N的一维向量,xi即为该向量中的第i个值,i取0时对应背景这一类别。经过softmax函数运算后,x中的数值全被转化为概率值,每个数值的大小即反应了像素属于对应类别的概率,且所有概率值之和为1。在softmax运算后,即可计算交叉熵损失函数。交叉熵损失函数:
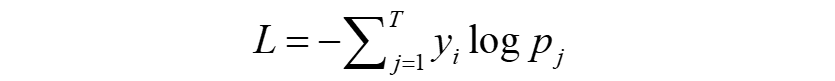
其中的p即为softmax函数的输出,y是一个向量,只有一个元素为1,其余元素为0,元素1的索引即为像素的真实标签。那么yjlogPj即计算第j个像素属于真实类别的概率值的log值。因为log函数是递增函数,所以概率值越大,函数值越大,那么-log函数值越小,所以预测为真实类别的概率值越大,损失函数值就越小。将所有像素的损失值求和或求平均就可得到一次训练的损失值。此后,在反向传播时就可以根据损失值更新网络参数。
(5)评价指标mIoU
交并比(Intersection over Union,IoU)是语义分割网络预测得到的类别区域和实际类别区域的交集与并集的比值,是语义分割的主要评价指标。若分割效果越好,则预测区域与实际区域越重叠,那么两者的交集越大且并集越小,从而IoU的值越大。因此IoU的值越大反映分割效果越好。
由于语义分割任务中往往有多个类别,因此会先计算出每一类别的IoU,然后对所有IoU求均值,即mIoU(mean Intersection over Union)。mIoU的计算公式如下: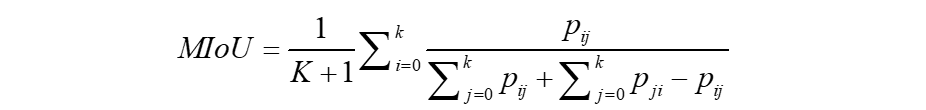

4.常用数据集PASCAL VOC 2012
PASCAL VOC 2012数据集是目前语义分割领域最常用、也是最基础的benchmark数据集,研究者常将其与Semantic Boundaries Dataset合并为PASCAL VOC 2012增强数据集后使用。此处仅对PASCAL VOC 2012数据集(以下简称VOC2012数据集)做简要介绍。
VOC2012数据集分类
VOC2012数据集分为20类,包括背景一共有21类,分别如下:
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
数据集下载
VOC2012数据集的官方下载地址为:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
文件目录
数据集下载完成并解压后得到的文件目录如下:
- VOCdevkit
- VOC2012
+ Annotations + ImageSets + JPEGImages + SegmentationClass + SegmentationObjectAnnotations文件夹中存放的是xml格式的标签文件;ImageSets文件夹中存放的是Action,Layout,Segmentation等任务对应的图像数据;JPEGImages文件夹中包含了PASCAL VOC提供的所有jpg图片,共计17125张;SegmentationClass文件夹中存放的是语义分割任务的标签图像;SegmentationObject文件夹中存放的则是实例分割任务的标签图像。
在用于语义分割的图片中,有1464张图片用于训练,1449张图片用于验证,1456张图片用于测试(下载的VOC2012数据集中没有测试集的标签图像,官方并没有发布出来)。
语义分割的原图像和标签图像示例如下:

在标签图像中属于不同类别的像素会被标记为不同的颜色,每一种类别对应一种颜色,包括背景共21种颜色。
5.语义分割的经典网络 Fully Convolutional Networks(FCN)
全卷积神经网络FCN是语义分割任务的经典模型。FCN的输入可以是任意尺寸的图像,通过采用转置卷积运算对网络末端的最后一个特征图进行上采样,可以得到与输入图像相同尺寸的输出。FCN可生成与输入图像同尺寸的逐像素标签,因此能够保留输入中的空间信息。通过在上采样得到的特征图上对所有像素进行分类,即可得到输入图像的语义分割结果。
FCN网络中有5个卷积块,每个卷积块由若干个卷积层后接一个最大池化层组成。根据分割结果的生成方式,可将FCN分为三种网络结构,分别是FCN-32s,FCN-16s以及FCN-8s。FCN-32s直接对FCN的末端卷积层的输出进行转置卷积来得到分割结果;FCN-16s首先对末端卷积层的输出进行转置卷积,然后将其与裁剪后的第四个卷积块的输出逐像素相加,最后对逐像素相加的结果进行转置卷积来得到分割结果;FCN-8s同样对末端卷积层的输出进行转置卷积,再将其与裁剪后的第四个卷积块的输出逐像素相加并转置卷积得到特征图,然后将特征图与裁剪后的第三个卷积块的输出逐像素相加,最后对逐像素相加的结果进行转置卷积来得到分割结果。由于网络的浅层输出包含了更多的细节信息,相比于FCN-32s和FCN-16s,融合了末端输出及多个浅层输出的FCN-8s具有更好的分割性能。
因此以下将以FCN-8s为例,对FCN的网络结构及运算过程进行介绍。

图中黑色矩形代表输入图像,蓝色矩形代表卷积层,绿色矩形代表池化层,灰色矩形代表裁剪操作,橙色矩形代表转置卷积运算,黄色矩形代表逐元素相加。将池化层及其前面的若干个卷积层视为一个卷积块,则FCN网络中一共有5个卷积块。图像在被第一个卷积块处理前会经过零填充操作以增大空间尺寸,此操作的目的是为了在最后一次转置卷积的输出中取出与输入图像空间尺寸相同的特征图。图中虚线的上半部分是网络的卷积运算部分,被零填充的图像会依次经过5个卷积块处理,然后再经过2层卷积层运算得到通道数较大的输出,图中虚线的下半部分是网络的预测部分,该预测部分共有三个分支,来自网络不同位置的输出将在各分支经过相应的处理,并被融合为最后的语义分割图。在第一个分支中,来自卷积运算部分的输出首先经过卷积层将通道数转变为类别数,然后经过转置卷积运算得到特征图1;在第二个分支中,对第四个卷积块的输出进行卷积运算和裁剪操作以得到和特征图1同空间尺寸和通道数的特征图2。进一步将特征图1和特征图2逐像素相加,再进行转置卷积运算得到特征图3;在第三个分支中,将第三个卷积块的输出进行卷积运算和裁剪操作以得到和特征图3同尺寸的特征图4。此后将特征图3和特征图4相加,再经过转置卷积和裁剪操作后可得到和输入图像同空间尺寸的网络输出。取出网络输出中每个像素对应的一维向量中最大值的索引,即可对每个像素预测类别,最后对不同类别的像素标上对应的颜色即可完成图像的语义分割。
-The End-
文案:廖政飞
指导老师:曹菁菁 赵强伟
排版:王雪 黄雅文