导读
还记得上一期用人体姿态估计的方式回看冬奥会精彩瞬间的视频吗?很多小伙伴私信小编是如何实现的,不要慌,本文就手把手教你如何用OpenPose实现人体姿态估计,助你光速拿捏~👌
1. OpenPose简介
OpenPose是由美国卡耐基梅隆大学Ginés Hidalgo, Zhe Cao, Tomas Simon等人基于卷积神经网络和监督学习并以caffe为框架开发的人体姿态识别项目,是世界上第一个在单个图像上联合检测人体、手、面部和脚关键点(总共135个关键点)的实时多人检测算法,也是目前最为常用的姿态估计算法之一。具有极强的鲁棒性,可应用于动作捕捉、行为识别、增强现实等场景。
效果展示:
2. OpenPose基本原理
现如今人体姿态估计的方法主要有两个方向:自上而下的方法和自下而上的方法。
- 自上而下(up-to-down)方法:是先利用目标检测的方法对图片中预测对象的位置进行标定,然后在对标定框中的预测对象进行骨骼关键点的预测。
- 自下而上(bottom-to-top)方法:先预测出图片中预测对象的关键点坐标,然后再将所有关键点进行聚类最后组成完整的预测对象。
OpenPose算法的基础理论是来自于一篇发表于CVPR 2017的文章《Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields》,该文提出了一种自底而上的方法,通过一个双分支的深度神经网络分别图片中的关键点和骨骼位置进行预测,再将所有关键点进行二部匹配组合成正确的人体骨架结构。
该算法的基本流程如下图所示:

整个网络以一幅大小为w × h的彩色图像作为输入(图a),生成图像中每个人关节点的图片坐标位置(图e)作为输出。通过一个双分支的前馈神经网络同时预测图片中人体关键点(如:肩膀、手肘、手腕等)位置的一组2D置信度映射(图b)和人体骨骼位置(如:颈部、大臂、小臂等)的一组2D部位亲和力向量场(图c),后者编码部位之间的关联程度。最后,通过贪心算法(图d)对置信度映射和亲和力场进行解析,输出图像中所有人的二维关键点。在前馈神经网络中,整个网络结构如下图:
从图中可以看出,整个网络被分成了两个分支,其中顶部分支(米色部分)用于预测部分置信度映射S,底部分支(蓝色部分)用于预测部分亲和力场L,每个分支都是一个迭代预测结构,可以使得结果在连续的迭代中不断细化。在第一阶段,输入是图片经过微调过的VGG-19的前10层提取的特征映射F,最随后的每一个阶段中,都是以前一个阶段的两个分支的预测与原始图像特征F的拼接作为输入。每个阶段以串联的方式进行连接,并在每个阶段的末尾处接入一个L2损失函数以产生不断改进的预测。
3. OpenPose运行
下面介绍一种简单的在Ubuntu平台上基于Docker实现的OpenPose运行方式,对于OpenPose其他安装方式感兴趣的也可以参考:
https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/doc/installation/0_index.md
- 下载安装docker
(docker的具体安装教程可以参考:
https://www.runoob.com/docker/ubuntu-docker-install.html)
- 从dockerhub中找到对应镜像(这里比较推荐cwaffles/openpose镜像),在命令行中通过以下命令拉取镜像源到本地。
docker pull $镜像名- 当镜像源下载完毕后,通过以下命令进入docker容器中。
docker run $镜像名 -it -gpus all /bin/bash- 在容器中通过以下命令进行视频和图像测试。
./build/examples/openpose/openpose.bin --video examples/media/video.avi或者
./build/examples/openpose/openpose.bin --image_dir examples/media/ --face --handOpenPose常用参数及说明:
--face: 开启 Face 关键点检测;
--hand: 开启 Hand 关键点检测
--video input.mp4: 读取 Video;
--camera 3: 读取 webcam number 3;
--imagedir $pathto_images: 运行图像路径内的图片;
--write_video $path.avi: 将处理后的图片保存为 Video;
--writeimages $folderpath: 将处理后的图片保存到指定路径;
--write_keypoint $path: 在指定路径输出包含人体姿态数据的 JSON, XML 或 YML 文件;
--display 0: 不打开可视化显示窗口,对于服务器部署和 OpenPose 加速很帮助;
--num_gpu 2:设置使用的GPU数量;
--model_pose MPI: 采用的模型Model,影响 Keypoints 的数量、运行速度和精度
4. OpenPose代码详解
下面介绍一种由OpenPose源项目库实现的caffe转pytorch版本,对该项目感兴趣的可以参考:
https://github.com/tensorboy/pytorch_Realtime_Multi-Person_Pose_Estimation
整个项目的主要文件结构如下所示:
其中/lib/network/rtposevgg.py中的getmodel()函数定义了OpenPose的主要网络结构首先可以通过输入主干网络(trunk)‘vgg19’或‘mobilenet’来选择主干网络。")
然后函数分别定义了openpose网络stage1和stage2-6的网络结构和相关参数。

最后函数定义了rtposemodel()类作为openpose的整体网络,由一层vgg19和6层双分支卷积网络组成。其中modeli1表示第1个分支,modeli_2表示第2个分支。
")
在forward()函数里,从stage1开始我们将model0的输出out1与本层网络在两个分支上的输出在通道维进行拼接并作为下一层的输入。
最终网络的输出为一个由两个分支网络在最后一层的输出组成的集合和一个记录所有层输出的列表。
/train/trainVGG19.py是主要的训练阶段代码,其中,triancli()和cli()为训练相关的参数设置函数,trainfactory()为数据载入函数,getloss()为loss计算函数,trian()函数为主要的训练函数,validate()为评估函数,AverageMeter()为计算和储存常用值的类。
其训练阶段实重用torch训练模板,首先引用/lib/network/rtposevgg.py中的getmodel()函数载入网络,并将网络参数传入至CUDA中。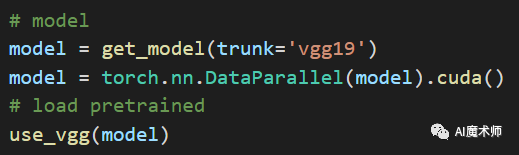
然后设置优化函数以及学习率优化策略,先进行5次不计算梯度的预训练。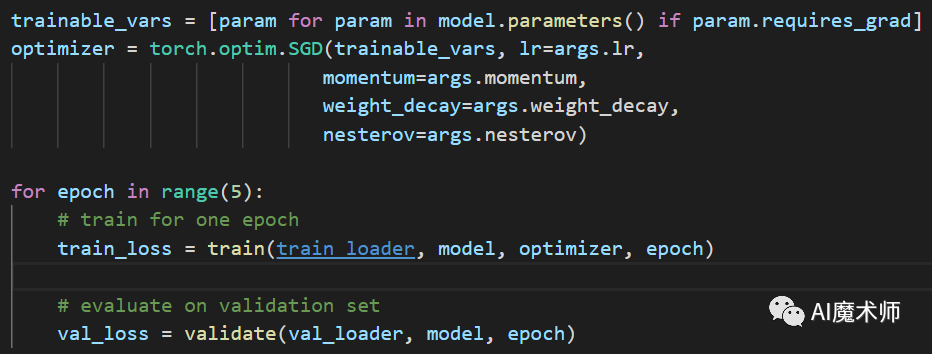
然后从第6次到第20次进行正式训练,并以ReduceLROnPlateau作为学习率的改变策略。
-The End-
文案:黄齐贤
指导老师:曹菁菁 赵强伟
排版:王雪 黄雅文